
机器代人、降本增效
智慧赋能、去繁化简
智能引导、未雨绸缪
概览
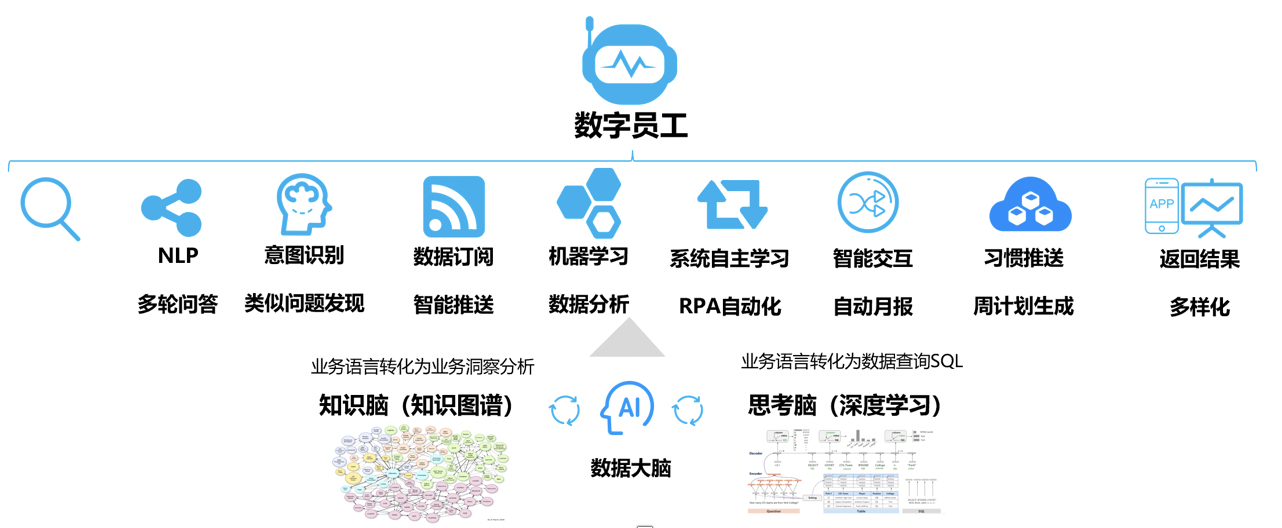
数字员工基于自然语言处理、知识图谱、向量引擎等人工智能技术,深度理解用户问题意图,为用户提供专业智能分析与指令服务。无需预先设计报表,通过语音、文字等交互形式即可查询结果。数字员工不仅能完成传统问答式BI内容(如明确问答、多轮问答、单维度/多维度问答、数据下钻、最值查询等),还能根据AI能力进行智能引导式服务(如模糊问答、提示性回答、比对性问答、动态生产表单/月报、关联性主动提示等)。
数字员工构建了专业语义库,不断积累领域知识,可以对各行业的专业术语进行精确理解与分析;内置智能操作指令集,只需语音控制即可完成打印文件、查看明细、图形转换、数据下钻、生成周报/月报、打开现场摄像头等各类复杂操作。同时,数字员工可以以移动APP、AR、VR、机器人等各种形态为企业服务,让服务无处不在。
主要优势
1.围绕专业领域构建专业语义库,易于推广且持续优化
目前生活化的语义识别已经比较完善,但一旦进入专业领域,人工智能变得不再智能,究其原因是对专业领域知识没有进行知识的图谱化、向量化,因此在实战中效果不好,更无法推广。围绕专业领域为构建语库知识库,易于实现突破,并构建出一套可持续性迭代优化的模型。
2.对于现有数据进行“价值化”,“资产化”使用示范
结合大量的非结构化数据、现有数据平台,结合机器学习能力,有力推动公司数字化转型,是实现业务数据化、数据业务化的重要抓手。
3.促进数据/组织统一协同
通过数据统计体系的建立,实现统一标准、统一模型、统一指标、统一架构、统一技术,解决数据“一个源”问题,以数据协同促进组织协同。
4.改变业务行为模式
通过人机语音、文字等智能交互,面向管理者,提供最及时、最优化的辅助决策方案;面向员工,使其从基础的重复性劳动中解放出来,从而创造更大价值。
5.能交流的报表和数据分析系统
数据包括结构化和非结构化数据,前者来源于各个业务系统或者机器产生的数据,后者的来源更为广泛,比如规章制度、工作流程等。
建立统一获取数据或者报表的入口非常重要,而这一入口如果是以语音和文本驱动的话,就可以更加人性化和节约大量的报表制作的时间。
能交流的报表和数据分析系统可以实现人机交互、模糊查询、机器学习、异常数据的监控、趋势的分析、KPI模型变等支撑管理部门领导和日常业务工作的高级应用。
功能特性
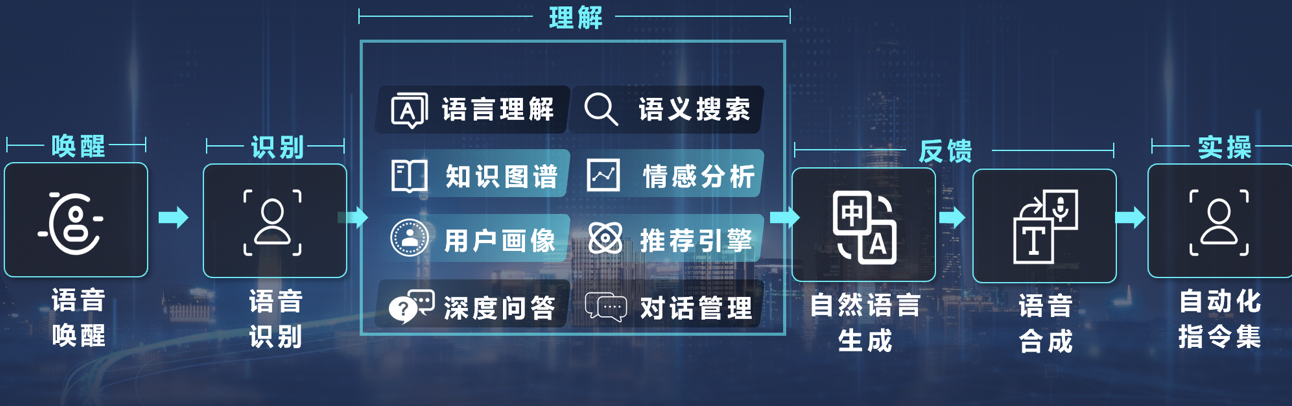
数字员工功能图说明如下:
人机交互主程序是前台的客户端,语音识别、知识图谱依赖于后端的管理平台。
功能特性 | 说明 |
语音识别
| 语音识别,是将一段语音信号转换成相对应的文本信息。 · 系统主要包含特征提取、声学模型,语言模型以及字典与解码四大部分; · 为了更有效地提取特征,还需要对所采集到的声音信号进行滤波、分帧等预处理工作,把要分析的信号从原始信号中提取出来;之后,特征提取工作将声音信号从时域转换到频域,为声学模型提供合适的特征向量; · 声学模型中再根据声学特性计算每一个特征向量在声学特征上的得分,而语言模型则根据语言学相关的理论,计算该声音信号对应可能词组序列的概率; · 最后根据已有的字典,对词组序列进行解码,得到最后可能的文本表示。 |
泛化相似问题管理
| 配置与标准问题相似的提问话术。用于语音对话套件中配置的标准问题,对于同一类问题,支持不同的提问方式。相似问题可配置多条。 · 新增:新增一条人机对话套件,对语音对话套件中的基本问题新增类似问题,以及状态(启用、禁止) · 编辑:选择一条对话套件进行编辑,修改相似问题及状态; · 停用、启用:选择一条对话套件进行停用、启用; · 展示全部状态:展示全部状态下的对话套件,包括使用中和停用状态。 · 展示使用中:仅展示使用中的对话套件 · 查询:按照套件名模糊查询对话套件 |
汇报模板和接口管理
| 在进行语音汇报时,对不同的问题作出对应的回答,确保提出的问题与语音助手回复的结果时一致的。进行汇报模板的编辑时,每一个提出的问题,以及相似问题,都只能获取到唯一的结果。用户可以自行添加和修改模板名称和标准话术,可以选择是否使用模板话术。支持对已有模板进行修改,更改使用状态等功能。
|
标签管理 | 定义页面标签的操作方式,包括单不限于登录、汇报、替代鼠标机型点击,可根据业务需求进行配置。与语音对话套件配置中的套件类型相关联,是套件类型配置的前置条件。 |
基于KG的命名实体识别 | 命名实体识别(Named Entities Recognition, NER)是自然语言处理(Natural Language Processing, NLP)的一个基础任务,其目的是识别语料中人名、地名、组织机构名等命名实体,在所有涉及NLP的人工智能研究中,如智能客服[53]等,都是一个必须首先攻克的任务。由于这些命名实体数量不断增加,通常不可能在词典中穷尽列出,且其构成方法具有各自的一些规律性,因而,通常把对这些词的识别从词汇形态处理(如汉语切分)任务中独立处理,称为命名实体识别。
命名实体识别的研究主体一般包括3大类(实体类、时间类和数字类)和7小类(人名、地名、机构名、时间、日期、货币和百分比)的命名实体。评判一个命名实体是否被正确识别包括两个方面:实体的边界是否正确;实体的类型是否标注正确。
目前,大部分问答系统都只能搜索答案,而不能计算答案。搜索答案进行关键词的匹配,用户根据搜索结果人工提取答案,而更加友好的方式是把答案计算好呈现给用户。通过算子识别+基于知识图谱的实体识别进行问题的初步解析,通过知识图谱来进行问题中元素的识别,通过算子识别得到可能触发的服务集合。。
|
用户意图识别(Intention Recognition)是对用户问题意图的理解,通常有基于规则模板的分类方法和基于机器学习的分类方法。
基于规则模板的分类方法比较适用于查询非常符合规则的类别,通过规则解析的方式来获取查询的意图。比如:今天天气怎么样,可以转化为[日期][实体:天气][询问词:怎么样]。上海到曼谷的机票价格,可以转化为[地点]到[地点][机票/车票/火车票]价格。但其限制的业务范围比较小,通常一类服务设计若干种模板,可复制性不高。同时用户查询稍作变换就无法进行正确理解,另外规则的发现和制定主要靠人工进行。
基于机器学习分类的使用场景为有确定的查询类别体系,基于机器学习进行意图的分类,通过分类特征的选择, 还有训练样本的准确标注来提高意图识别的准确率。
|
